01PART语音识别基础知识
语音识别是语音交互中最为重要的一项,语音识别技术用于将声学语音进行分析,并得到对应的文字或拼音信息。语音识别原理流程:输入—编码—解码—输出。
1.语音输入
通过麦克风将声波转换成电信号,即声波—>模拟信号—>数字信号,后续操作中的例如编码、解码等工作,这都是基于数字信号进行的处理。

2.编码(特征提取)
①分帧
对于电脑来说连续的一整段声音是无法识别的,需要对声音进行分帧。所谓分帧,也就是把声音切成一小段一小段,每一段就是一帧。
②声学特征提取
分帧后语音就变成了许多小段,然后根据MFCC(梅尔频率倒谱系数)特征和人耳的生理特性,把每一帧变成一个多维向量。
3.解码和搜索
语音识别流程中解码就是通过声学模型,字典,语言模型对提取特征后的音频数据进行文字输出。
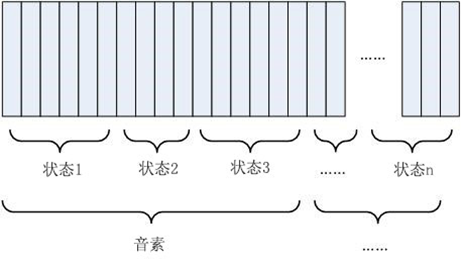
①声学模型
•将这些上面步骤中的帧信息识别成状态(可以理解为中间过程,一种比音素还要小的过程)。
•若干帧对应一个状态,再将状态组合形成音素(通常3个状态=1个音素)
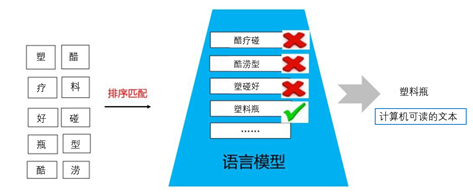
②字典
将前边步骤中组成的音素,每若干个组合成字词并串连成句,例如(sù liào píng)。

③语言模型
音素组成语言的形式需要用到语言模型,语言模型是使用大量的文本训练出来的,通过对大量文本信息进行训练,得到单个字或者词相互关联的概率,将前边的字词放入到语音模型中进行排序搜索和匹配。
4.输出
最后将根据声学模型和语言模型得到的字词句以文本的形式进行输出。
NLP 即“自然语言处理” ,用于将用户的指令转换为结构化的、机器可以理解的语言。
TTS 即“从文本到语音”,是人机对话交互的一部分,让机器能够说话。即语音合成,从文本转换成语音,让机器说话。
02PART语音识别案例
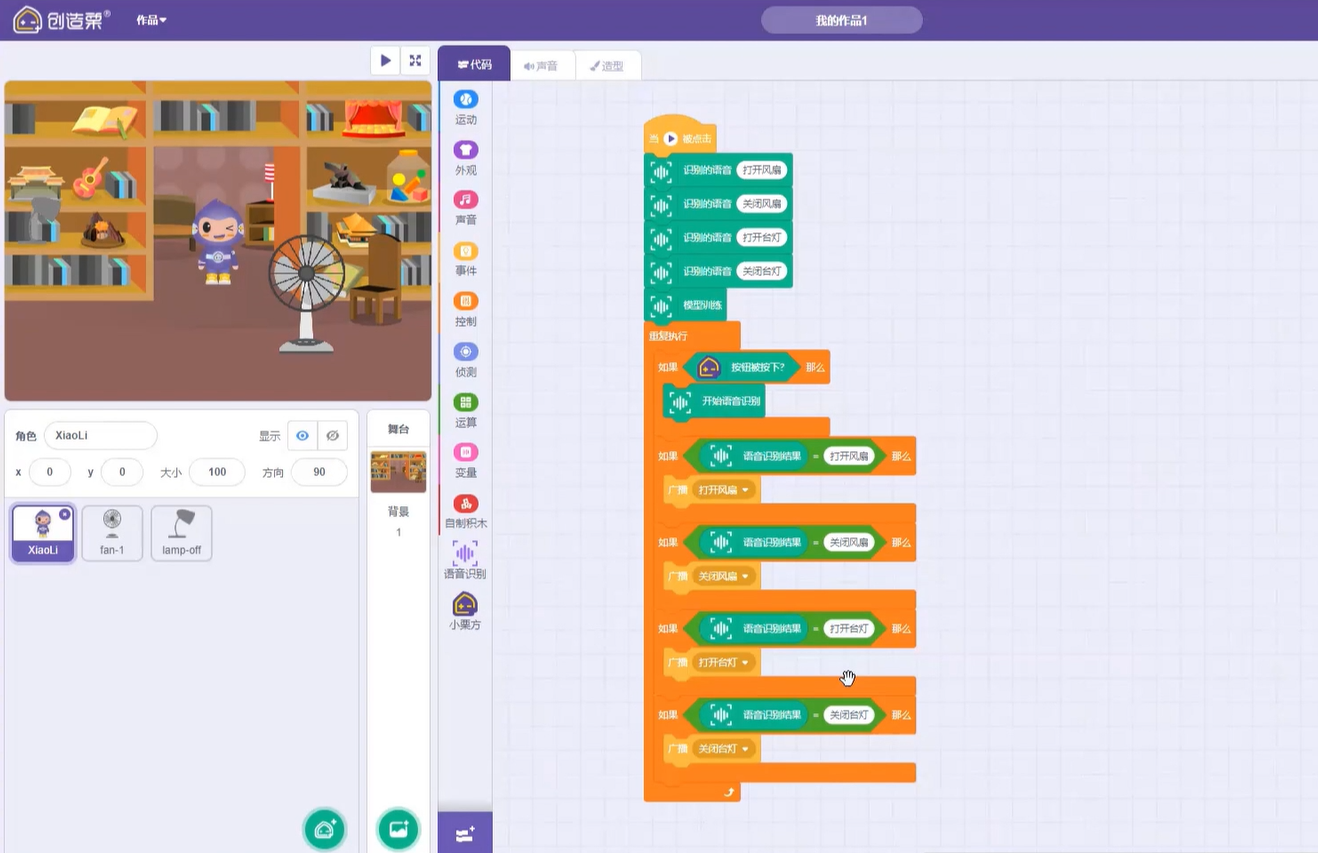
>> 示例程序包下载地址
链接:
https://pan.baidu.com/s/16eH35e6QNUSa8LV8GRPgBg?pwd=t8ly
提取码:t8ly
>> 案例讲解视频
后台回复PAAT即可获得培训回看
